
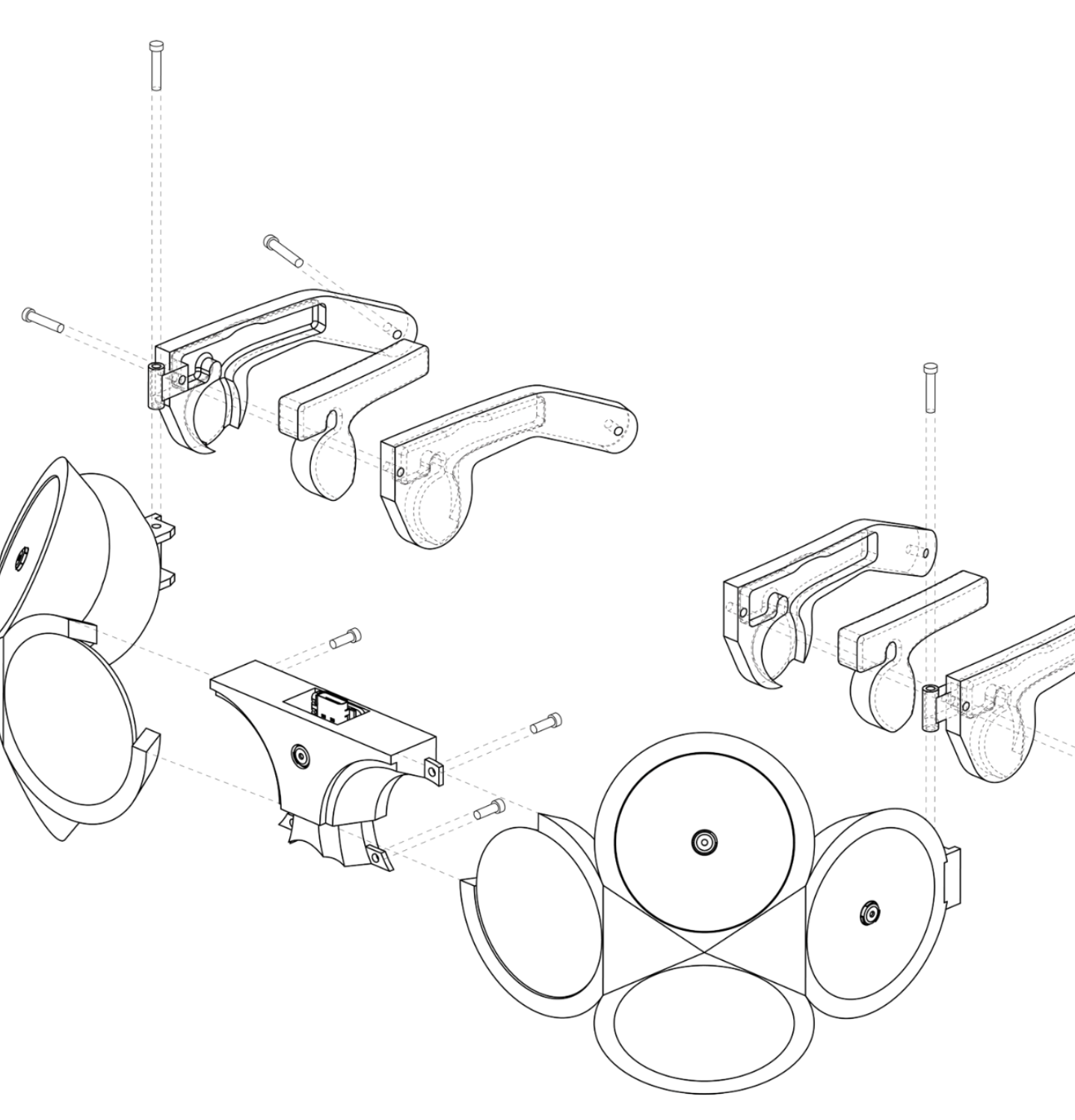
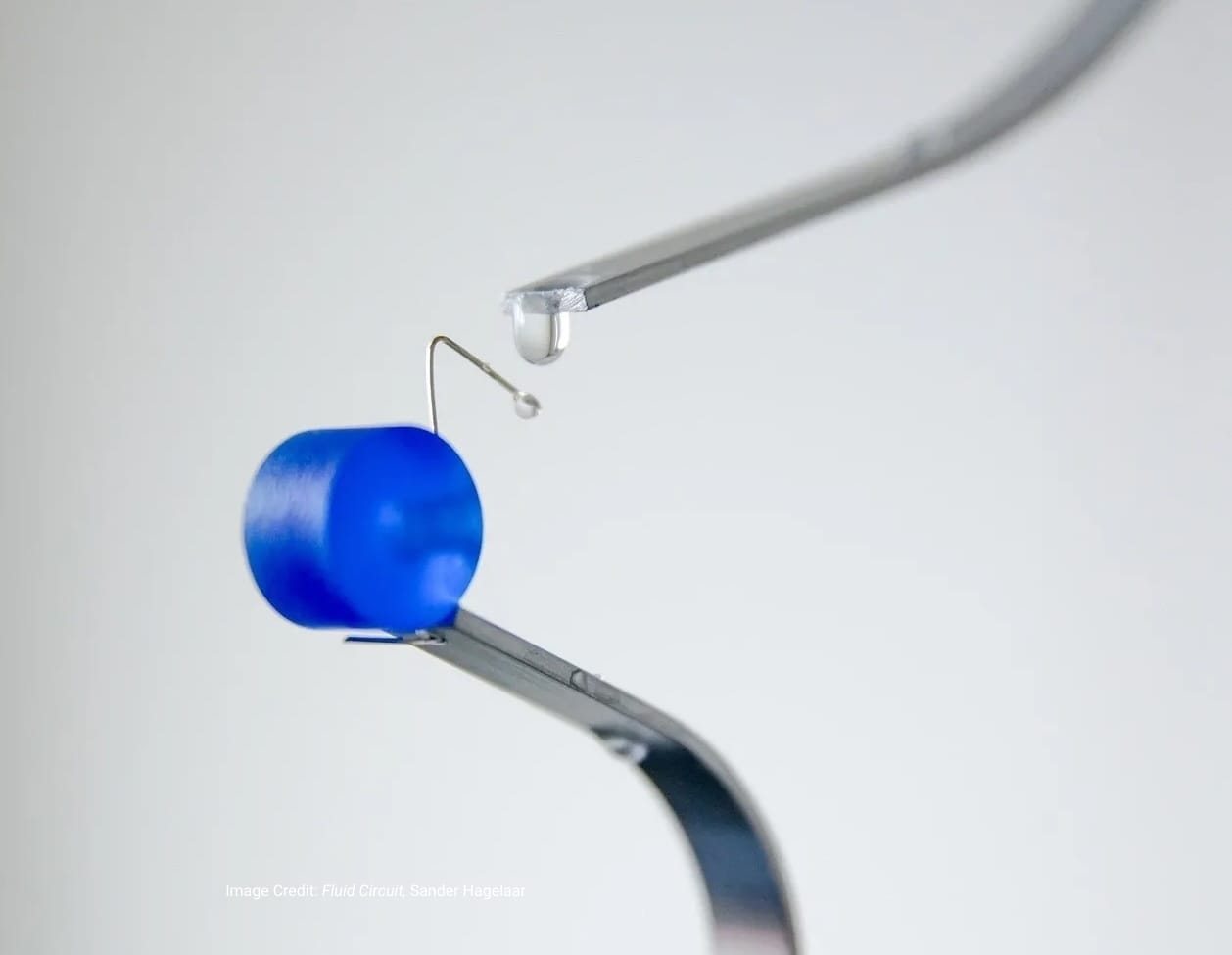
NOEMA is a spatial audio project that investigates how machine intelligence might operate beyond the visual interface. Developed by Melo Chen and Nomy Yu for Interaction Intelligence at MIT (taught by Marcelo Coelho, with support from William McKenna and teaching assistants Sergio Mutis), the project functions as what the designers describe as a “large language object.”


Rather than generating text or images for a screen, NOEMA segments and reconstructs perception through sound. The system delivers spatialized audio experiences—ambient cues, narrative fragments, and musical elements—that respond to context and reshape how a listener interprets their surroundings. In this configuration, sound is not supplementary; it is the primary interface.

The project reframes AI as an atmospheric layer rather than a discrete output mechanism. Instead of presenting information visually, NOEMA positions machine intelligence as an interpretive presence—an inner voice that describes, questions, and reframes what is sensed. This shift foregrounds listening as an active mode of interaction and suggests alternative models for human–AI engagement rooted in embodiment and spatial awareness.
By relocating computation from screen-based display to acoustic space, NOEMA examines how perception changes when intelligence is encountered as environment rather than image.
Project Info
Developers: Melo Chen and Nomy Yu
Year: 2025
Image Credit: NOEMA by Melo Chen & Nomy Yu




{kind=link}