
Scale has defined machine learning for more than a decade. Foundation models are trained on scraped web corpora and optimized through centralized cloud infrastructure. Performance is measured in parameters and benchmarks. More data, more compute, more reach. Yet across artistic and research practices, a different logic is emerging—one that treats scale not as destiny but as design.
Dataset minimalism does not simply mean “small models.” It means interrogating how datasets are assembled, what they extract, and what their expansion requires. The politics of AI are embedded not only in model architectures but in the construction of their training ground. The contrast becomes clearer when looking at three distinct but interconnected approaches: Memo Akten’s constrained neural networks, Kate Crawford and Vladan Joler’s infrastructural cartographies, and Joana Moll’s quantification of digital extraction.
Building Within Limits: Memo Akten
In 2017, Memo Akten presented Learning to See, an interactive installation in which a neural network was trained on images captured live through a webcam. Rather than depending on a vast pre-scraped internet corpus, the system learned from a locally generated dataset shaped by participants in the space. Visitors could watch the training process unfold and observe how specific examples influenced the model’s output.

The project made a foundational aspect of machine learning visible: models reflect the structure of their training data. When the corpus is small and legible, causality becomes easier to trace. Misclassification is not an abstract glitch—it reflects what the system has or has not been shown. Akten has spoken about how bias and opacity are embedded in training data. By working with purpose-built datasets, the focus shifts upstream. Instead of treating bias as a downstream bug to patch, dataset construction becomes a primary design concern.
Mapping the Infrastructure of Scale: Crawford and Joler
In Anatomy of an AI System (2018), Kate Crawford and Vladan Joler mapped the supply chains behind a single consumer device: the Amazon Echo. The diagram traced lithium and rare earth mineral extraction, global logistics, data labor, and server infrastructure—demonstrating that AI systems depend on vast material and human networks. Their later project, Calculating Empires (2023), expanded this analysis historically and geopolitically, charting how computational systems have consolidated political and economic power across centuries.
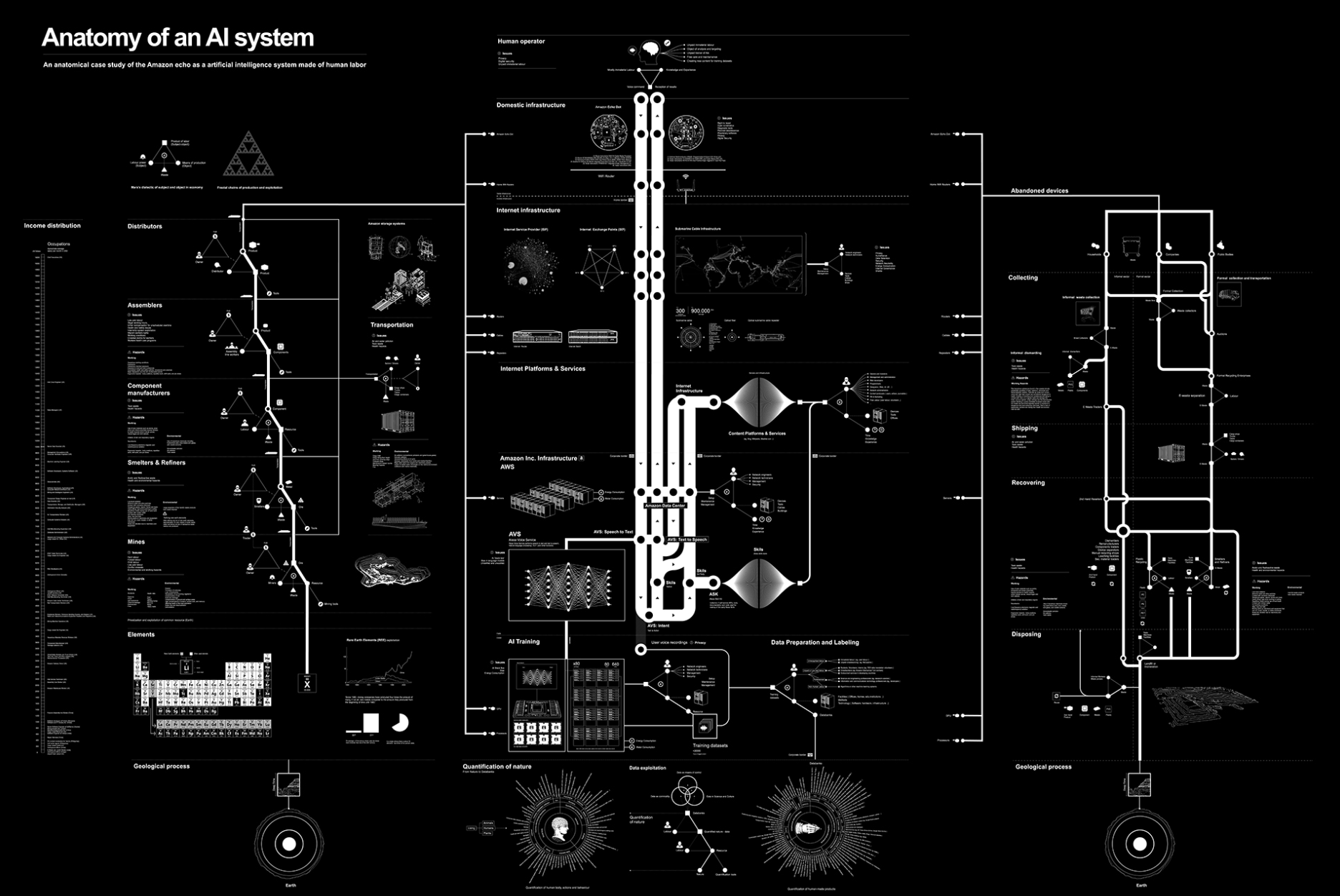
Where Akten makes dataset construction legible at small scale, Crawford and Joler expose what large-scale systems obscure. The project suggests that scaling AI systems entails expanded material, labor, and energy infrastructures. Scale is infrastructural. Seen from this vantage point, dataset minimalism is not aesthetic restraint. It is a structural intervention. Limiting data aggregation limits the expansion of the infrastructures that sustain it. But infrastructure is not only visible in supply chains. It is measurable in energy consumption and tracking systems that operate quietly in the background of everyday digital life.
Measuring Extraction: Joana Moll
Joana Moll’s practice quantifies the hidden material costs of digital systems. In CO2GLE, she calculates the carbon emissions generated by Google searches. In The Hidden Life of an Amazon User (2019), she traced the tracking mechanisms and data flows embedded in a single user session, revealing the complex web of third-party exchanges behind routine interactions.

Moll’s work does not train models; it measures the infrastructures that enable large-scale data capture. By translating digital processes into energy consumption, economic value, and environmental impact, she reframes scale as material burden. As datasets expand, storage and compute demands increase. As models scale, so do the data center infrastructures required to sustain them. The abstraction of “big data” carries measurable physical consequences.

Placed alongside Akten’s constrained training systems and Crawford and Joler’s cartographies, Moll’s quantifications complete the picture. Small datasets are not inherently virtuous, but they are more traceable. Their dependencies are easier to identify.
Designing Against Extractive Scale
Taken together, these practices reposition dataset minimalism as a design stance. Akten demonstrates how working with bounded corpora clarifies authorship and bias. Crawford and Joler reveal that large-scale AI systems depend on expansive material and geopolitical infrastructures. Moll measures the environmental and economic costs embedded in digital accumulation.
The through-line is visibility. At industrial scale, causality disperses across continents and supply chains. At smaller scales, relationships tighten. Decisions about inclusion, labeling, storage, and consent become more explicit. Dataset minimalism does not reject machine learning; it questions the assumption that performance must scale with extraction. It treats scale as optional rather than inevitable. As generative systems proliferate, pressure to expand training corpora will continue. These practices suggest another metric for rigor: not only how well a model performs, but how clearly its dataset can be traced—who contributed to it, what infrastructures sustain it, and what consequences it produces. In that sense, designing with less is not a retreat from AI. It is a demand for accountability in how intelligence is constructed.








{kind=link}